
-
añadir a favoritos


¡Llévelo, no lo necesitamos!
lunes, 23 de enero de 2017
Filtraciones, filtraciones... ¿Cómo los malintencionados reciben nuestros datos? Una parte de filtraciones se refiere, por supuesto, a hackeos que se realizan gracias a vulnerabilidades en las redes corporativas o errores de configuración. Pero también hay filtraciones particulares, un poco “tontos” que difícilmente pueden llamarse “filtraciones”, porque en este caso los titulares de estos datos los comparten públicamente. ¿Cómo pasa eso?
Todos sabemos que existen servicios de búsqueda. Los robots de búsqueda localizan los recursos disponibles en Internet para indexarlos y, usando los algoritmos “chamánicos”, visualizan los resultados de solicitudes de usuario. Pero no todos los recursos se indexan. Además– un recurso le puede indicar al robot de búsqueda si algún documento debe estar disponible para todos. Lo que pasa es que los robots de búsqueda, al localizar algún sitio web, no empiezan a indexar la información enseguida. Primero buscan el archivo robots.txt – un archivo de texto en la carpeta raíz del sitio web que contiene instrucciones para robots de búsqueda. Estas instrucciones pueden prohibir la indización de algunas secciones o páginas del sitio web, indicar la copia espejo correcta del dominio, recomendarle al robot de búsqueda cumplir con un intervalo temporal determinado al descargar los documentos del servidor, etc.
Por ejemplo, la entrada en el archivo Disallow: /about prohibirá acceso a la sección http://__nombre del sitio web__/about/ y al archivo http:// __nombre del sitio web__/about.php.
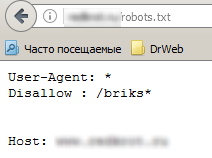
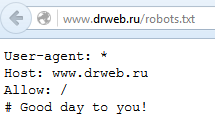
Pero en caso de saber que el archivo robots debe ubicarse en el catálogo raíz del sitio web, se puede abrirlo directamente, al indicar la ruta en el navegador. Y al abrir el archivo, se puede ver las líneas el acceso a las cuales está cerrado para robots de búsqueda.
Vamos a abrirlo y vemos:
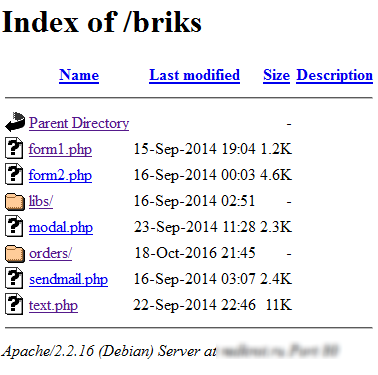
¿Y qué está en la carpeta? ¡Correcto, los documentos secretos!

Además, los enlaces a «los sitios secretos» pueden estar ubicados directamente en el código de la página principal:

¿Qué pasa por culpa de los desarrolladores del sitio web distraídos? Por ejemplo, Vd. crea su propio sitio web o ayuda a un conocido a hacerlo – hoy día es bastante fácil crear un sitio web. Como no se entera de la búsqueda de vulnerabilidades, confía este trabajo a profesionales, y lo hace bien. Y de repente encuentra un sitio web que ofrece servicios similares, mucho más barato que habitualmente …
No vamos a revelar la dirección del sitio web por razones obvias, pero este caso es muy reciente e ilustrativo.
Así el hacker que obtiene acceso necesario sabe de qué sitio web duda la gente en cuanto a la seguridad, cómo se llama el administrador de sistemas, su número de teléfono etc. Aunque no es ningún hacker, es un usuario avanzado …
Todo esto sería una tontería si esta búsqueda o permitiera encontrar los documentos secretos de empresas bastante importantes.
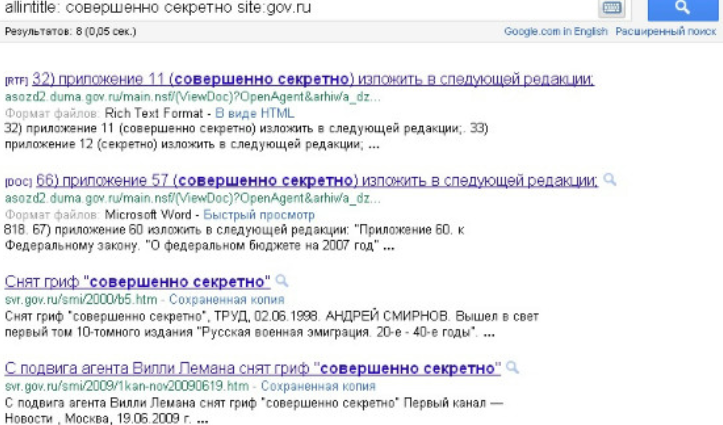
Los documentos de sitios web de varias entidades rusas, marcados con «difusión limitada», aparecieron en los resultados de sistemas de búsqueda el día 27 de julio de 2011. Los documentos con el sello de reservado de varias entidades y ministerios rusos han podido ser localizados en todos los buscadores más importantes: «Yandex», Google, Mail.ru и Bing.
Anteriormente, a la red se filtraron más de 8 miles de mensajes SMS enviados desde el sitio web del operador “Megafon”, los estados de pedidos de tiendas en Internet, incluidos sex shops, así como los datos de pasajeros del ferrocarril desde los sitios web Tutu.ru y Railwayticket.ru. Estaban disponibles públicamente los datos personales de clientes de tiendas: su nombre y apellidos, los artículos pedidos, la dirección de entrega, el correo electrónico y los datos de pasajeros – nombres y datos de billetes, algunos dígitos de números de pasaportes de pasajeros.
http://ekb-security.ru/news/2970-lr-lr-google.html
El mundo de antivirus recomienda
¡Confía, pero comprueba! Y para los aficionados a secretos: ¡no les ocultamos ningún secreto!
![[Twitter]](http://st.drweb.com/static/new-www/social/no_radius/twitter.png "Compartido 15 veces")
Nos importa su opinión
Para redactar un comentario, debe iniciar sesión para entrar en su cuenta del sitio web Doctor Web. - Si aún no tiene la cuenta, puede crearla.